Thinking about "Defer decision"
In Uncle Bob’s book <<Clean Architecture>>, he mentioned:
A good architecture allows you to defer critical decisions, it doesn’t force you to defer them.
He also mentioned:
…, if you can defer them, it means you have lots of flexibility. Because when you delay a decision, you have more information when it comes time to make it.
“Defer decision” allows you to do just enough things, just like simple design, or MVP(Minimum Viable Product). If you decide too many things in advance, the architecture will probably get more and more complex during the development.
There is a scenario I found in my project which is a good example for “Defer Decision”, so in the next let’s walk through the whole “Defer” journey.
Background
There are two applications: MainApp and IntegrationApp. People plan orders from MainApp, and then synchronise them to IntegrationApp. The orders are stored in different format between these two systems, and we name them MainAppOrder and IntAppOrder. MainApp uses an sync api to send the orders to IntegrationApp. The payload of the api is defined by IntegrationApp. The process looks like below:
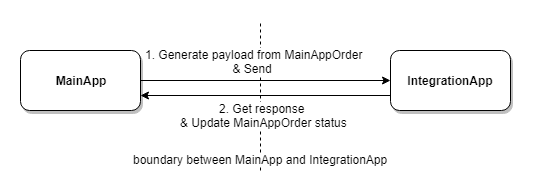
The IntegrationApp api only only supports single order sync, if the user tries to synced multiple orders to IntegrationApp, those orders will be done one by one.
Current Design
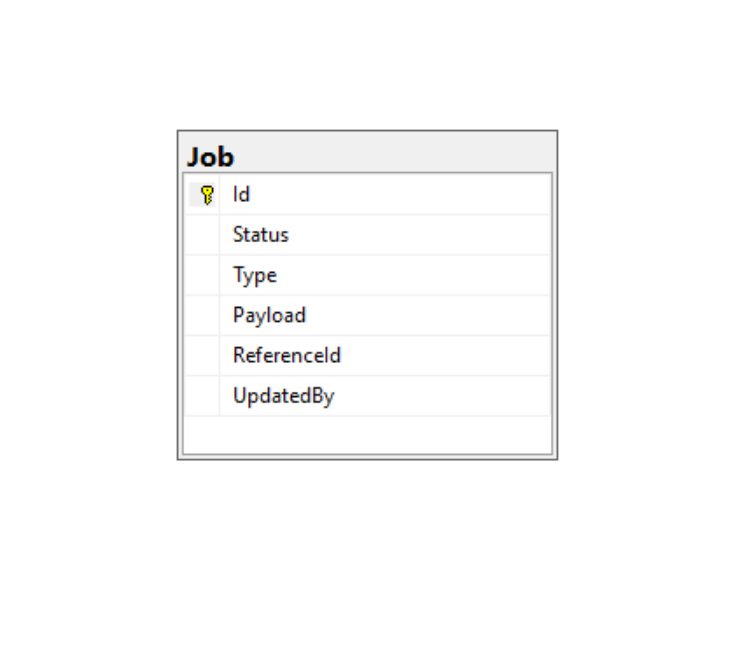
People using MainApp tend to do the synchronization for many orders together after they planned orders for a certain period, so the synchronization process may take several minutes to finish. In order not to block the user after they click the ‘Sync’ button on the page, we introduced Job Queue into the system, and simply create jobs for the orders. During Job creation, we generate the payload according the api contract, and save it into the database. We defined a Job table to store all the jobs, the definition looks like:
Then, there is a separate Job Runner to execute the jobs and sync to data to IntegrationApp. The workflow looks like:
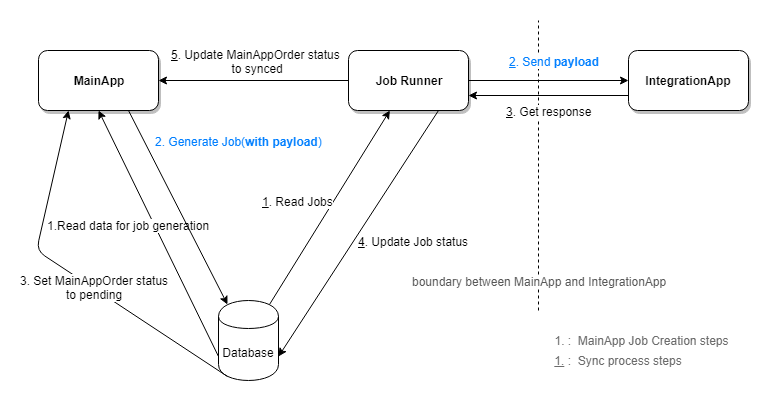
[Note:] In the diagram, all the sync steps happen after the Job Creation steps finished.
The Job Runner will run every n minutes to sync the data to IntegrationApp. For convenience,the payload we stored in the Job is in the format of the request body that send to IntegrationApp. There are actually 3 applciations in the system now: MainApp, Job Runner, IntegrationApp.
The benefit by storing the payload in database is that we can check the payload send to IntegrationApp api easily. But at the meantime, it brings us some troubles, one of which is that We need to maintain the payload stored in the job. For example, when IntegrationApp api payload changed, and if there are still some jobs with the old payload not executed yet we have to think about how to handle them.
Re-think with “Defer Decision”
If we think about the “Defer Decision” here, we can see that actually we don’t need to generate the job payload in advance. Instead, we can generate the payload when we are executing the job. As the payload generation requires some basic information(we can call it metadata), like the MainAppOrder’s OrderId, we need store the metadata of payload into the job.
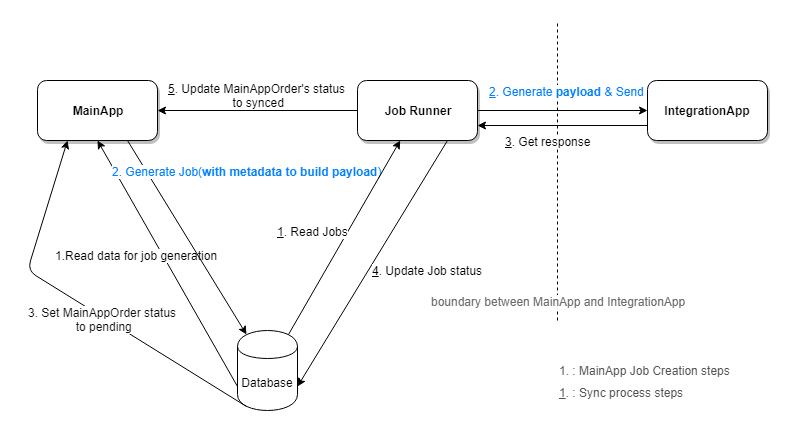
In this way, if the IntegrationApp api changed, the Job Runner can easily handle this situation by only changing the payload generation logic.
Some people may ask, “what if the metadata need to be changed?” The metadata we are talking here is the “just enough” information to build the payload. It is more stable compared with the payload itself.
Another benefit of “Defer Decision”
After I digged deeper into the code, I found that there is an IntegrationApp api call when generating the Job and payload. The reason is that some data required in the payload which is obtained from another IntegrationApp call.
So the work flow becomes:
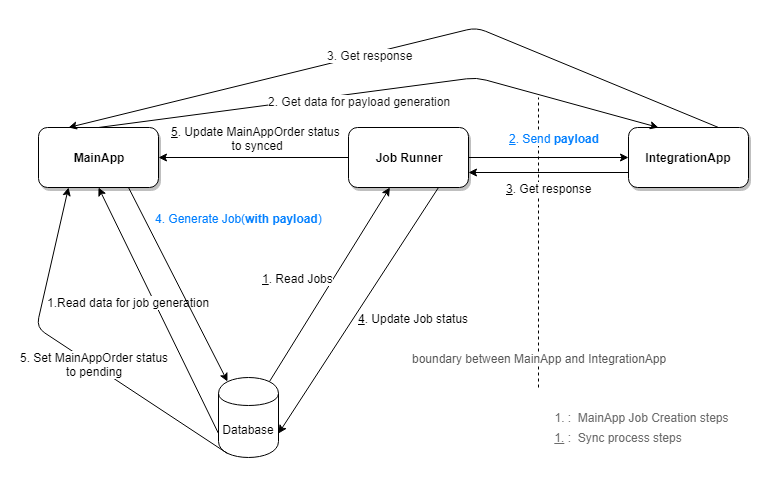
From the diagram, we can see that there is a dependency on IntegrationApp during the Job creation process. If the api call failed, the job won’t be created.
The diagram here is a simple version of the real use case, actually the Job creation process is within a MainAppOrder Approval process, which means that the MainAppOrder Approval process will fail if the Job creation failed. All this means that the approver cannot approve a MainAppOrder just because the payload syncing to IntegrationApp is not generated.
This is not a necessary restriction for the approver, and what’s even worse, the approver can do nothing when this happen. With applying “Defer Decision”, we can only store the metadata in Job, and then generate the payload from it just before sending to IntegrationApp. In this case, the MainApp approver can approve orders successfully, and the Job Runner will take care the payload generation and retry logic if any failure happened.
Further Discussion
Actually there are some benefits/considerations with the current design(storing payload directly), we list them in the below to see if they can still be covered in the “Defer Decision” design.
1. Job Runner can be a generic service, which should not care about the payload generation.
I agree that some Job Runners can be independent, like sending email. But some Job Runners may have some other operations before/after Job executed, like in Step 5, after the payload sent, there is an api call to MainApp to update MainAppOrder status.
Different Job Runners have different logic to consume the job data(metadata for payload generation), which can be scoped in the specific Job Runner itself. The Job Queue itself(the structure of storing the Job, the way to add/read jobs from the Queue) is generic. The consumer of the message data is context related. If you are familiar with Amazon SQS(Simple Queue Service) or Microsoft Azure Queue Service, you will know what I mean.
You may ask, “Why do not consider the payload as the message data”? In our example, there are two reasons that we can’t think the payload as message data:
-
If we think the Job Runner and MainApp as a system, which makes sense when comparing with IntegrationApp system, the consumer is also the producer. The integration between MainApp and IntegrationApp is not pub-sub pattern.
-
Usually the two parties of api contract, or the message producer and consumer do not have equal voice. For pub-sub pattern, the publisher usually decide the format of message data. In our system, the payload is decided by IntegrationApp system.
2. Generating and keeping payload in Job table is more convenient for supporting.
It makes sense that storing the payload for supporting, as you can easily tell what’s the data sent to the other system.
With storing metadata for payload generation, we can still still keep the payload column in the Job table, and set its value right after it ‘s generated. So there are two columns in Job table: column Metadata and column Payload.
3. Maintaining the metadata also needs effort.
This is the main point we discussed in this blog. Generally speaking, the metadata is more stable than the payload generated with it. What’s more, we have more control on metadata than payload, as the metadata is defined inside our system.
Wrap-up
We discussed a scenario in which the “Defer Decision” strategy is a more suitable choice. In most cases, it makes sense to not rely on the data which are likely to change often, otherwise we will spend more effort to handle with the “temp data” which generated in the process.
Furthermore, what we discussed here is not only about “Defer Decision”, but also about defining the boundary between systems, or even different processes within one system.
All in all, there is no best, only better. The important thing is to choose the one fit.
blog comments powered by Disqus